



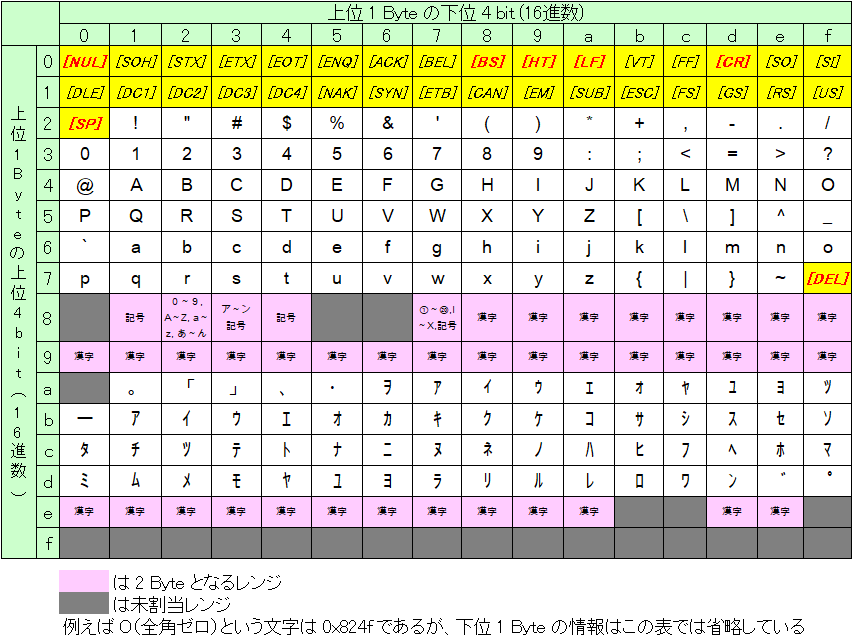
HULFTで使用している1バイトコードには、ASCIIの文字コードとEBCDICの文字コードの2種類があります。コンピュータで扱う文字の種類。 数字、アルファベット、半角のカタカナなど、1バイトの情報量で識別できる文字を指す。 1バイトコード文字は、いずれも半角文字となる。コンピューターの情報量を表すときに使用される単位。 1バイトは半角英数字1文字分の情報量。 全角文字の場合1文字で2バイトの容量を必要とする。
1文字は1バイトですか?日本語などの全角文字1文字は、2バイトに相当します。
アスキーコードは1バイトですか?
8ビット目を利用した拡張規格
ASCIIでは1文字を7ビットで表すが、現代のコンピュータのほとんどはデータの基本的な管理単位が1バイト(8ビット)であるため、実際には1文字を8ビットで表している。英数字は ASCII コードによって1文字で1Byte、日本語文字は Shift JIS コードに よって1文字が2 Byte で表現されることがわかった。
1バイト文字コードと2バイト文字コードの違いは?
説明: 漢字やひらがななど、2バイトの情報量で識別できる文字のことで、全角文字という。 それに対してアルファベットや数字、カタカナなど、1バイトの情報量で識別できる文字のことで、1バイトコード文字、半角文字、ANK文字という。

バイト(Byte)は、8桁の2進数のことで、1バイト=8ビットのデータを表します。
なぜ1バイトは8ビットなのでしょうか?
8という中途半端な数字である理由は何でしょうか。 答えはアルファベット1文字が8ビットだからです。 英文字のAやBなど小文字も含めて表すには、8ビットが必要です。 そのため1バイトは8ビットとして基準が定められたのです。説明: アルファベットや数字、カタカナなど、1バイトの情報量で識別できる文字のことで、「半角文字」「ANK文字」ともいう。 それに対して、漢字やひらがななど、2バイトの情報量で識別できる文字のことを2バイトコード文字や全角文字という。ASCIIでは1文字を7ビットで表すが、現代のコンピュータのほとんどはデータの基本的な管理単位が1バイト(8ビット)であるため、実際には1文字を8ビットで表している。
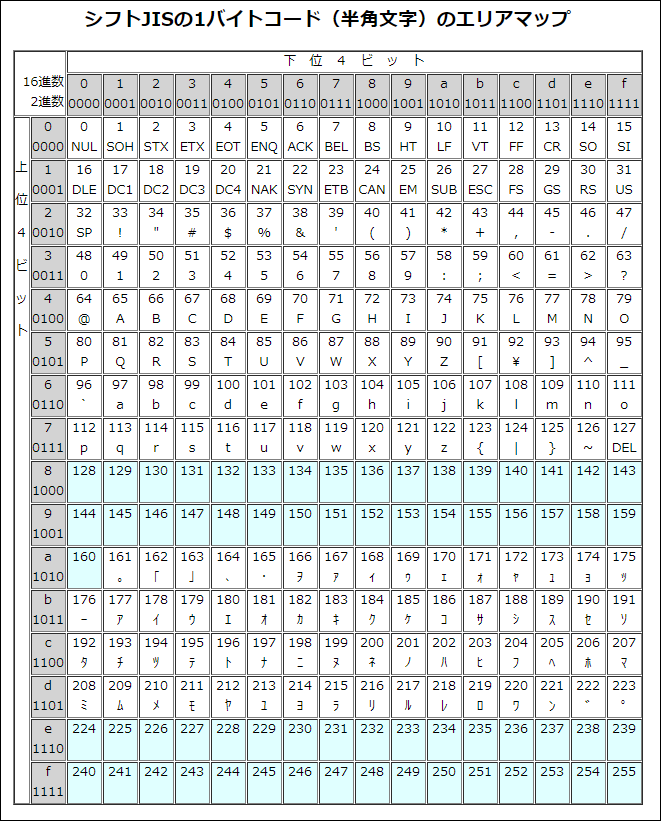
現在でも使用されている日本語の文字コードとしては次の4種類がある。
- ISO-2022-jp (JISコード)
- EUC-JP (Extended Unix Code)
- Shift-JIS (SJIS)
- Unicode.
- nkfコマンドを使う
- Emacsを使う
- VS Codeを使う
- 半角カナ
1バイトと2バイトとは何ですか?キーワードは「ビット」と「バイト」です。 1ビット(bit)はコンピュータが扱う最小単位で、2進数の1桁を表します。 ビットが8個集まると1バイト(Byte)です。 つまり、1バイトで2進数の8桁を、2バイトでは16桁(=2×8)を扱うことができます。
Utf-8の文字コードは1文字何バイトですか?全角文字の1文字はEUC、SJIS文字コードでは2バイトですが、UTF-8文字コードに変換すると3バイトまたは4バイトになる場合があります。 また、半角カナ文字の1文字はEUCコードでは2バイト、SJISコードでは1バイトですが、UTF-8文字コードの場合は3バイトとなります。
1バイトは8bitですか?
コンピュータの世界では、1バイト(Byte)= 8ビット(bit)と定義されておる。 1bitとは、コンピュータが扱うデータの最小単位のこと。 コンピュータの世界ではすべての情報が2進数で処理されているが、その1桁のことを1ビット(bit)という。

1バイトで表現できる文字に分類されるのは、主にアルファベットや数字です。通常,8ビットを1バイト(Byte)と呼ぶ. また,ネットワークについて議論する場合には,8ビットを1オクテット(octet)と呼ぶこともある. なお,ビット,バイトを記号で表す時,b, Bをそれぞれ使用する.1バイト文字(半角文字)はJISローマ字コードのみで、 半角カタカナ等は使ってはならない。 直接入力モードでキー入力できる文字ならば大丈夫である。 日本語入力モードの変換の際に、 半角カタカナや半角句読点等に変換してしまわないように注意すること。