



方法は簡単で、ある文字の直後にカーソルを置いてから[Alt]+[X]キーを押す。 するとカーソルの直前の文字がUnicodeの文字コード番号に変換される。Unicode とは、世界の様々な言語、書式、記号に、番号を割り当てて定義した標準の文字コード です。 一つ一つの文字 に番号を割り当てることで、プログラマーは、どの言語が混ざっていても、コンピューターに保存、処理、伝送させるような文字エンコーディングを同じファイルやプログラムの中に作ることができます。UTF-8(ユーティーエフエイト)は、Unicode文字のエンコード方法の1つです。 Unicodeは、世界中に存在するさまざまな言語の文字を統一して使えるようにするためのコードセットになります。 そして、UTF-8はグローバルにもっともポピュラーで基礎的な文字コードの1つです。

Unicodeが使われる理由は何ですか?Unicodeの狙いと特徴
全ての文字種を同じように扱えるため、言語の種類によってプログラムを変更する必要がなく、文字列部分さえ翻訳すれば、簡単に多言語化/国際化できる(実際には、各国固有の機能の追加も必要になるが)。
Unicode変換のやり方は?
Unicode 文字を挿入する
Alt + X キーを押すとコードが記号に変換されます。 Unicode 文字を別の文字の直後に配置する場合は、Alt キーを押しながら X キーを押す前にコードだけを選択します。その1、Ctrl+Shiftを押し続けるやり方
Ctrl+Shiftを押し続けます。 Uキーを押します。 コードポイントを押します。 Ctrl+Shiftを離すと、Unicode文字が入力できます。
Unicodeのひらがなは1文字何バイトですか?
(a) UnicodeとCOBOLの文字数
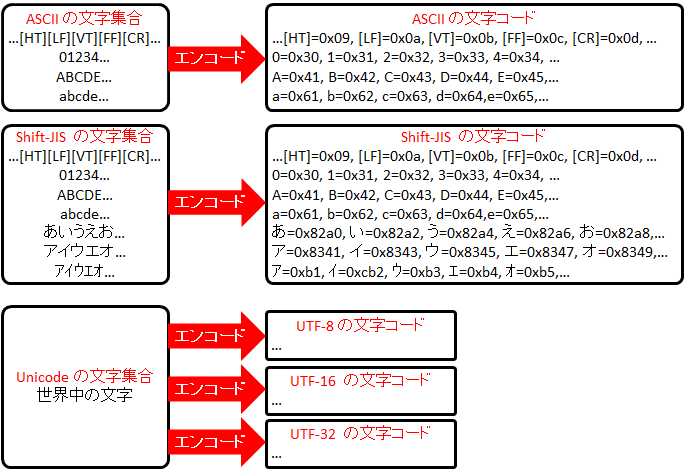
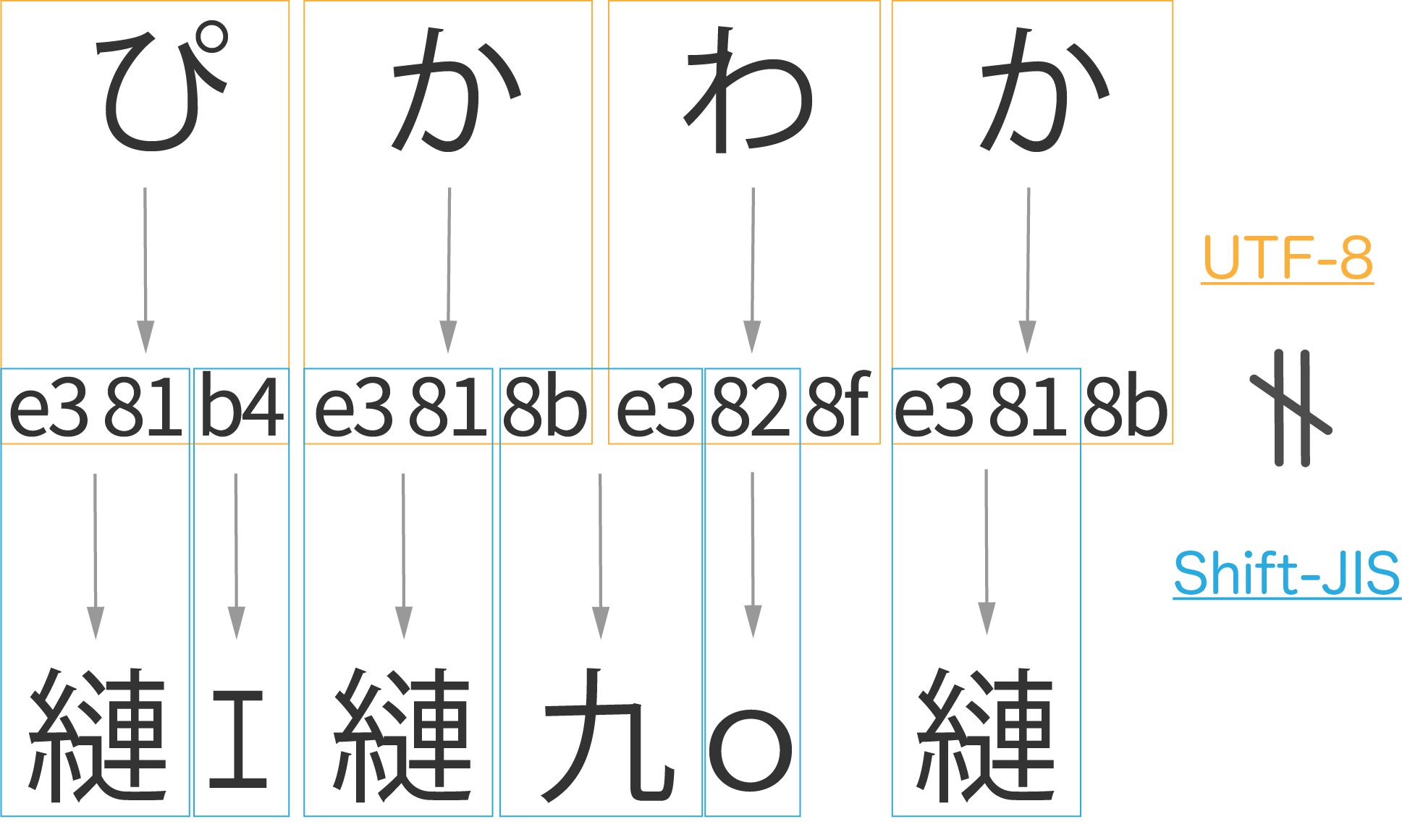
シフトJISでは,1文字のバイト数は半角1バイト,全角2バイトと決まっていますが,Unicodeでは,1文字のバイト数は文字によって異なります。 例えば,UTF-8では半角英数字は1文字1バイトですが,半角かたかなは1文字3バイト,全角日本語は3~8バイトの可変長になります。
Unicodeは2Byteで文字を表現するため、最大65,536文字が表現可能である。
Utf-8の欠点は何ですか?
欠点
- UTF-8による符号化では、漢字や仮名などの表現に3バイトを要する。
- 最短ではない符号やサロゲートペアなど、UTF-8の規格外だがチェックを行わないプログラムでは一見正常に扱われるバイト列が存在する。
Altキーを押してメニューバーを表示させ、ファイル→名前を付けて保存よりダイアログを開きます。 そして画面下の「エンコード」がUnicode(UTF-8)に設定されていることを確認して保存しましょう。 ちなみにファイルの種類よりWebページ形式とテキストファイル形式が選択できるので任意の保存形式を選択してください。様々なコードがある中で、Unicodeでは顔文字や天気、動物といった絵文字を使用する事が可能となっており、現在ではパソコンを含めスマートフォンにも普及し様々な場所で利用されています。 分かりやすいものであれば、スマホで打つメールやSNSのFaceBook等で用いる絵文字などがそうです。
概要 Unicodeは世界で使われる全ての文字を共通の文字集合にて利用できるようにしようという考えで作られ、Unix、Windows、macOS、Plan 9などの様々なオペレーティングシステムでサポートされている。 Javaや. NETのようなプログラミング環境でも標準的にサポートされている。
Unicodeを表示するには?Word の段落に入力した文字の右側にカーソルをおいて [Alt] キー + [X] キー を押すと、カーソルの左側にある文字が Unicode での表示に切り替わるため、文字コードを調べることができます。
文字コードのunicodeを調べるには?特定の文字の Unicode の文字コード値を調べるには、次の作業を実行します。
- 文字コード表を起動します。
- [フォント] ボックスで、使用するフォントをクリックします。
- 使用する特殊文字をクリックします。 選択した文字に対応する Unicode の文字コードが、ウィンドウの右下のボックスに表示されます。
Unicodeの日本語の文字はいくつのバイトで表されますか?
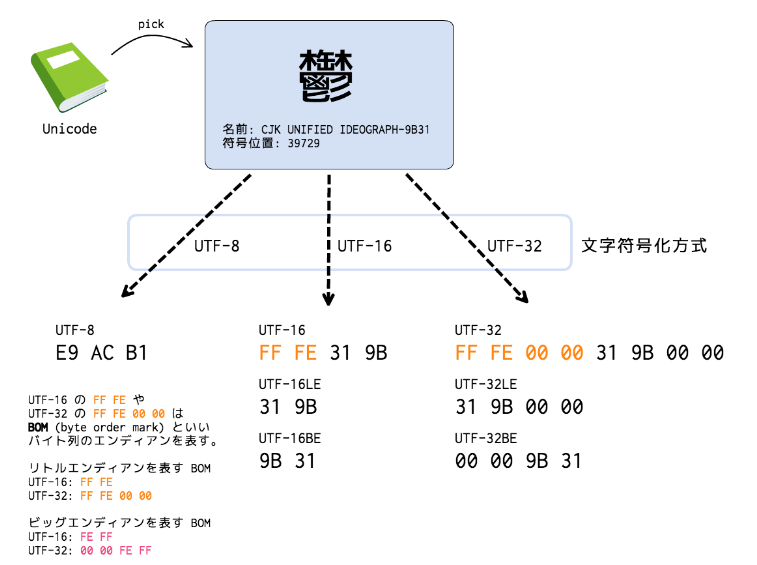
Unicode で一番よく利用される形式。 ASCIIは1バイト、日本語は3バイトで表現。 Unicode を 16ビットで表現。 Unicode を 32ビットで表現。
Unicode は、エンコードされているデータのデータ・タイプに基づいて、8 ビットと 16 ビットの 2 つのエンコード形式を使用します。 デフォルトのエンコード形式は 16 ビットで、各文字の幅は 16 ビット (2 バイト) です。しかし、UTF-8は英数は1バイトで表現し、日本語は3バイトで表現するようになっています。 つまり、英数の割合が多い場合はUTF-8の方が効率が良いのですが、日本語が多い場合はUTF-16の方が効率が良いといえます。 また、世界的に見ればUTF-8を標準として使用することが多くなっています。MS-Officeアプリケーション(Excel、Word、Access等)はUnicodeに対応していますが、同様にVBAはUnicodeに対応しています。 文字列型(String)も、内部的にUnicode(UTF-16)が使用されていて、文字列処理関数などはそのまま利用できます。