



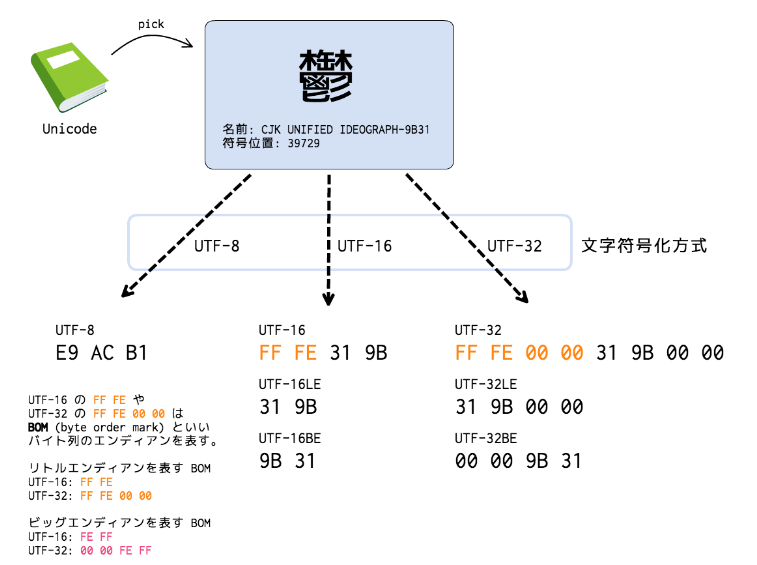
(c)UTF-16. BOM付きの場合を「UTF-16」、BOMなしで Big-endian の場合を「UTF-16BE」、BOMなしで Little-endian の場合を「UTF-16LE」 と呼びます。UTF-16 (16-bit UCS Transformation Format):
UCS-2で定義される文字集合を用いて記述された文字列に、UCS-4の一部の文字を埋め込むためのエンコード方式。 UTF-8と併用することができる。 UCS-2で利用できる文字数を大幅に増やすことができる。このプロパティーを使用して、指定されたパラメーターによって使用される 1 文字あたりの最大バイト数を指定します。 UTF8 は 1 文字あたり 3 バイトを含み、UTF16 は 1 文字あたり 2 バイトを含みます。
Utf-8とutf-16のどちらがいいですか?基本的には、UTF-8かUTF-16で全言語まかなえる。 UTF-32は固定長がありがたい環境向け。 UTF-8は、ASCIIコード付近のバイト数が少なく、英字が多いなら総バイト数が小さくなる。 UTF-16は、日本語が3バイトらしく、日本語が多いなら総バイト数が小さくなる。
Utf-16には何種類ありますか?
UTF-16. 厳密にいえばUTF-16には3種類あり,それぞれUTF-16,UTF-16BEないしUTF-16LEと呼びます。 BEはビッグエンディアン 'Big Endian', LEはリトルエンディアン 'Little Endian' の略です。文字コードの範囲が広く、ほとんど文字化けしない
UTF-8はUnicodeの一種なので、文字コードの種類も豊富です。 カバー範囲も広いため、世界中のどの言語においてもほとんど文字化けしません。
UTF16の可変長は?
また,UTF-16でも,全角日本語は2バイト,4バイト(サロゲートペア文字),6~8バイト(IVS文字)の可変長となります。
欠点
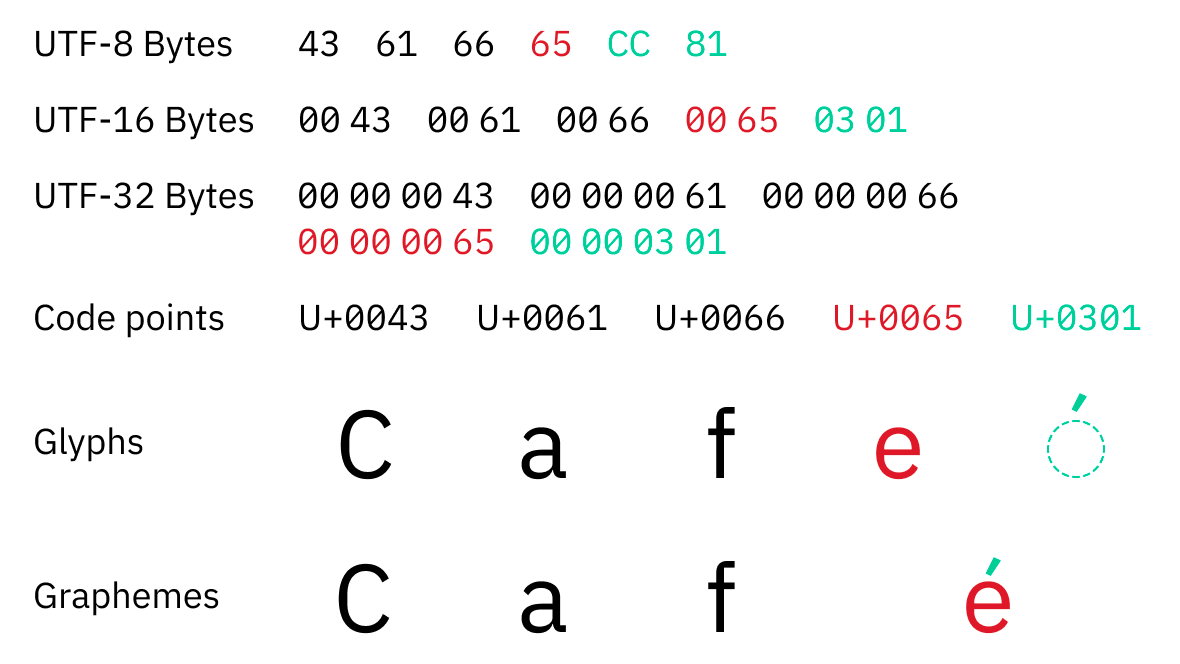
- UTF-8による符号化では、漢字や仮名などの表現に3バイトを要する。
- 最短ではない符号やサロゲートペアなど、UTF-8の規格外だがチェックを行わないプログラムでは一見正常に扱われるバイト列が存在する。
utf16の可変長は?
また,UTF-16でも,全角日本語は2バイト,4バイト(サロゲートペア文字),6~8バイト(IVS文字)の可変長となります。入力データがUNICODE(UTF16)コード系の場合、以下の点に留意して帳票および入力データを設計してください。 項目長は、日本語文字(半角カタカナを含む)は1文字3バイト、半角英数字は1文字1バイトで計算して項目長を指定してください。固定長フィールドには決められた長さ(文字数、けた数)のデータしか入力できないが、可変長フィールドは設定したデータの長さの範囲で自由にデータを入力できる。

固定長(CHAR型)とは、「入るデータの長さが決まっている」ということ。 例として、社員番号や郵便番号の文字列を格納する時に使われる。 可変長(VARCHAR型)とは、「中に入るデータの長さが決まっていない」ということ。 例として、氏名や書籍名といった文字列を格納する時に使われる。
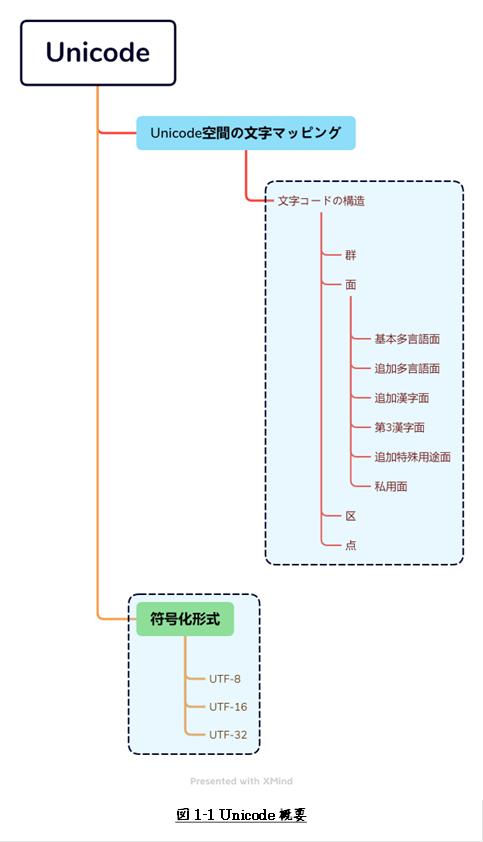
Utf-16の文字コードの範囲は?UTF-16エンコーディング
最初の16ビット値は0xD800から0xDBFFの範囲内でエンコードされます。 次の16ビット値は0xDC00から0xDFFFの範囲内でエンコードされます。 補助文字を使用すると、UTF-16文字コードは100万種類以上の文字を表現できます。
Utf-16の文字サイズはいくつですか?UTF-16 データは、2 バイトまたは 4 バイトの文字を持つことができます。 UTF-16 データは、CCSID (*UTF16) または CCSID (1200) の UCS-2 として定義されます。 EBCDIC 混合 SBCS/DBCS データは、1 バイトまたは 2 バイトの文字を持つことができます。
固定長方式とは何ですか?
固定長フォーマットとは? 各項目の文字列が使用する長さも決まっている形式を示す。 余分なスペースがある(逆に文字列の長さが足りない場合もありえる)のでそのときどきによって使用する。

かへん‐ちょう〔‐チヤウ〕【可変長】
長さ・桁数・文字数・データの大きさなどが定まっていないこと。 特に、コンピューターで、レコード(ファイルを構成する単位)の長さが変えられる形式を指す。 ⇔固定長。こてい‐ちょう〔‐チヤウ〕【固定長】
長さ・桁数・文字数・データの大きさなどが定められていること。固定長データ (定位置データ) は、各レコードの長さが決められた、シンプルなレコード・コレクションです。