



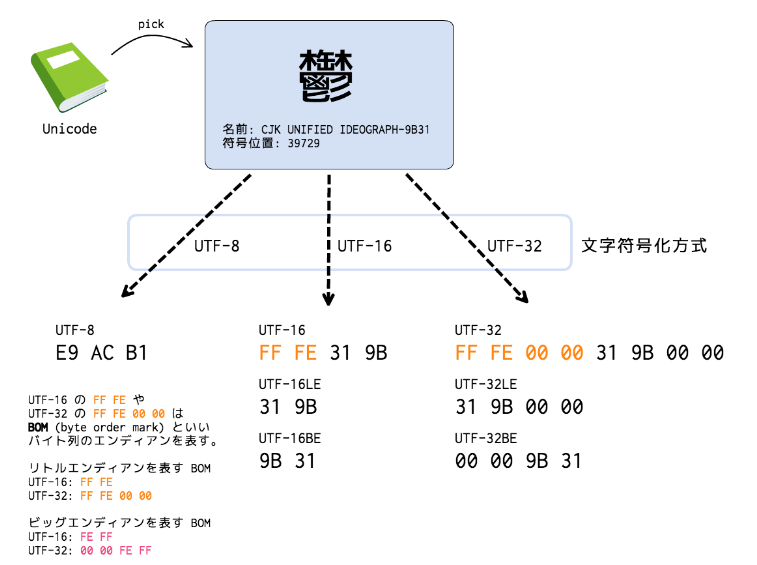
基本的には、UTF-8かUTF-16で全言語まかなえる。 UTF-32は固定長がありがたい環境向け。 UTF-8は、ASCIIコード付近のバイト数が少なく、英字が多いなら総バイト数が小さくなる。 UTF-16は、日本語が3バイトらしく、日本語が多いなら総バイト数が小さくなる。欠点
- UTF-8による符号化では、漢字や仮名などの表現に3バイトを要する。
- 最短ではない符号やサロゲートペアなど、UTF-8の規格外だがチェックを行わないプログラムでは一見正常に扱われるバイト列が存在する。
UTF8 は 1 文字あたり 3 バイトを含み、UTF16 は 1 文字あたり 2 バイトを含みます。 ASCII 文字は、1 バイトでその文字自体を表します。
SJISとUTF8のどちらを選べばよいですか?CSV形式でデータをダウンロードするとき、「Shift-JIS」と「UTF-8」のどちらを選べばよいですか 基本的にWindowsの場合は「Shift-JIS」を、macの場合は「UTF-8」を選んでください。 Shift-JIS:Windowsで一般的に使用される文字コードです。
utf-8とutf-16LEの違いは何ですか?
使い分ける必要はありますか? UTF-8とUTF16の違いを一言でいうと、文字を表現するときの単位が違います。 UTF-8は8ビットの可変長マルチバイトで文字を表現し、UTF-16は16ビットの可変長マルチバイトで文字を表現します。例えば,UTF-8では半角英数字は1文字1バイトですが,半角かたかなは1文字3バイト,全角日本語は3~8バイトの可変長になります。 また,UTF-16でも,全角日本語は2バイト,4バイト(サロゲートペア文字),6~8バイト(IVS文字)の可変長となります。
Utf16の利点は何ですか?
UTF-16 (16-bit UCS Transformation Format):
UCS-2で定義される文字集合を用いて記述された文字列に、UCS-4の一部の文字を埋め込むためのエンコード方式。 UTF-8と併用することができる。 UCS-2で利用できる文字数を大幅に増やすことができる。

文字コードの範囲が広く、ほとんど文字化けしない
UTF-8はUnicodeの一種なので、文字コードの種類も豊富です。 カバー範囲も広いため、世界中のどの言語においてもほとんど文字化けしません。
Utf-16とutf-16LEの違いは?
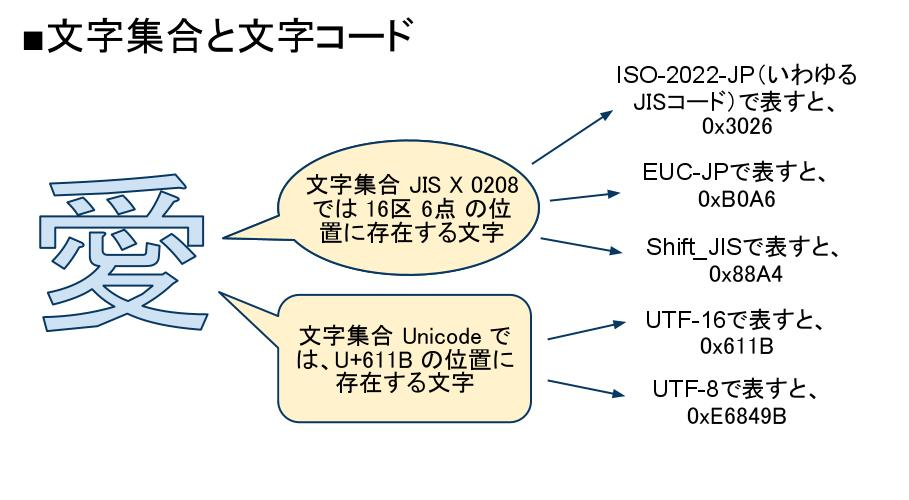
(c)UTF-16. BOM付きの場合を「UTF-16」、BOMなしで Big-endian の場合を「UTF-16BE」、BOMなしで Little-endian の場合を「UTF-16LE」 と呼びます。全角文字の1文字はEUC、SJIS文字コードでは2バイトですが、UTF-8文字コードに変換すると3バイトまたは4バイトになる場合があります。 また、半角カナ文字の1文字はEUCコードでは2バイト、SJISコードでは1バイトですが、UTF-8文字コードの場合は3バイトとなります。UTF-8とUTF16の違いを一言でいうと、文字を表現するときの単位が違います。 UTF-8は8ビットの可変長マルチバイトで文字を表現し、UTF-16は16ビットの可変長マルチバイトで文字を表現します。

UTF-16とは UTF-16とは、Unicode、または、UCSを16ビットを単位とした可変長マルチバイトでエンコーディングする方式のことである。 2バイトで定義されているコード(U+0000~U+D7FFF、U+E000~U+FFFF)はそのままで、サロゲートペアで定義されているコードは4バイトにエンコードされる。
Utf-8の日本語は何バイトですか?また、UTF8コードの日本語文字を使用する場合は、1文字を6バイトに換算した値となります。
Utf-16は何バイトですか?UTF-16の場合,Unicodeの基本多言語面の全角文字は2バイトで表現するため,TEST-DATA2は2けた必要となります。 UTF-8の場合,Unicodeの基本多言語面の全角文字は3バイトで表現するため,TEST-DATA3は6けた必要となります。